🗓️ Week 07
Automated Data Collection I
22 Nov 2024
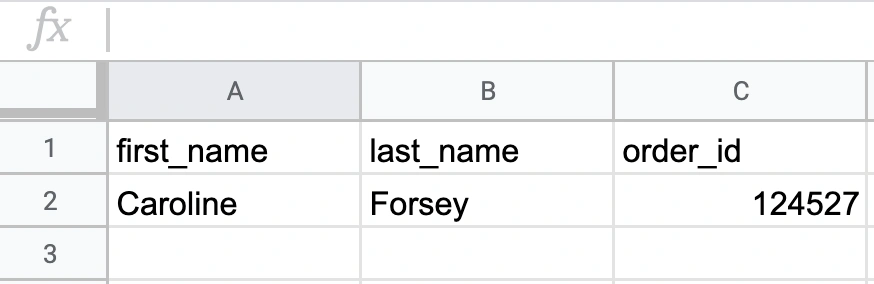
What is semi-structured data?
It does not conform to a data model but has some structure
It is not stored in rows and columns
This type of data contains tags and elements (Metadata) which is used to group data and describe how the data is stored
Similar entities are grouped together and organised in a hierarchy
Examples: HTML (e.g. websites), XML (e.g. government data), JSON (e.g. social media API)

Data revolution
HTML - elements
An HTML element is defined by a start tag, some content, and an end tag
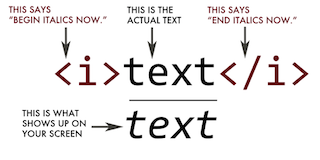
| Tag | Meaning |
|---|---|
<head> |
page header (metadata, etc.) |
<body> |
holds all of the content |
<p> |
regular text (paragraph) |
<h1>,<h2>,<h3> |
header text, levels 1, 2, 3 |
ol,,<ul>,<li> |
ordered list, unordered list, list item |
<a href="page.html"> |
link to “page.html” |
<table>,<tr>,<td> |
table, table row, table item |
<div>,<span> |
general containers |
HTML - attributes II
CSS anatomy II

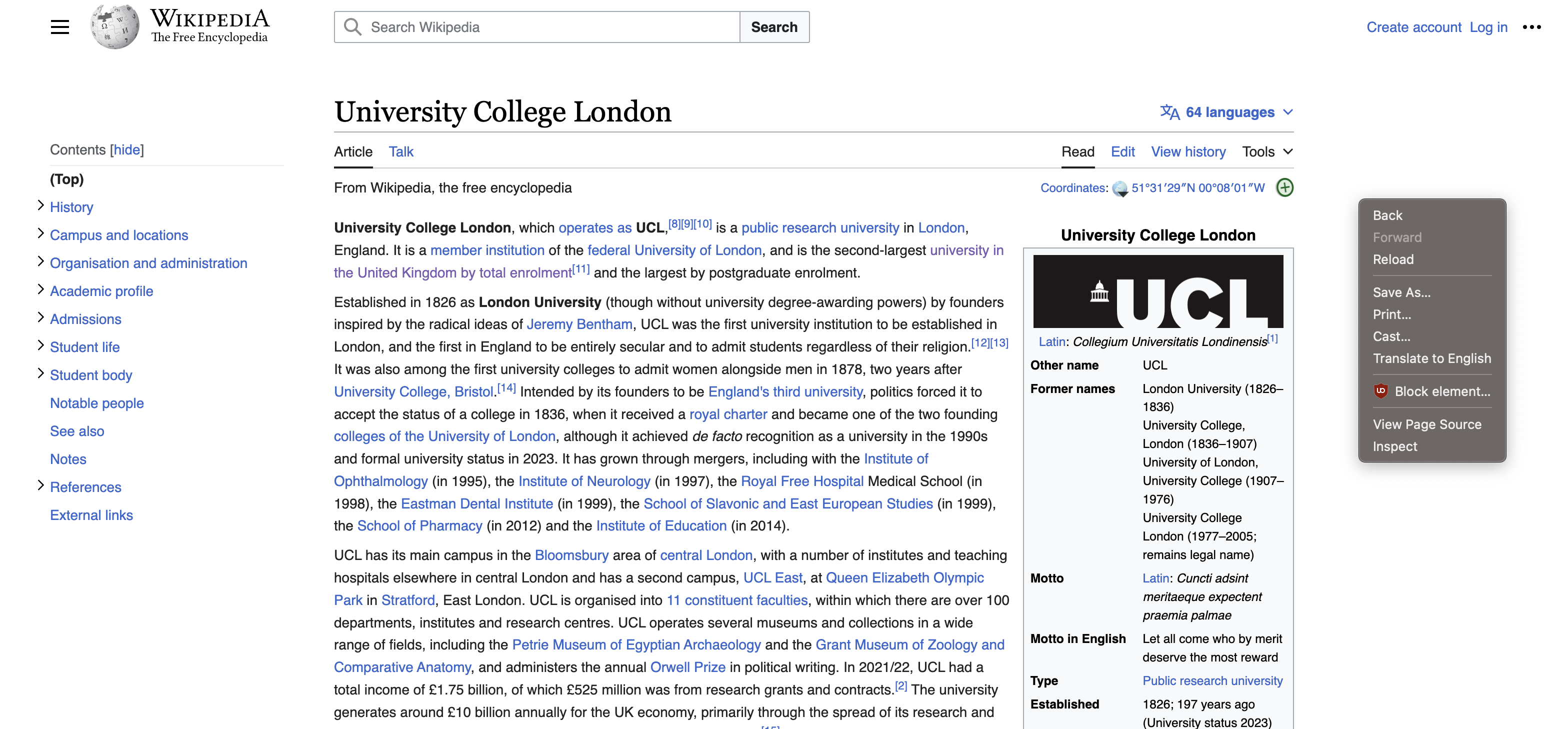
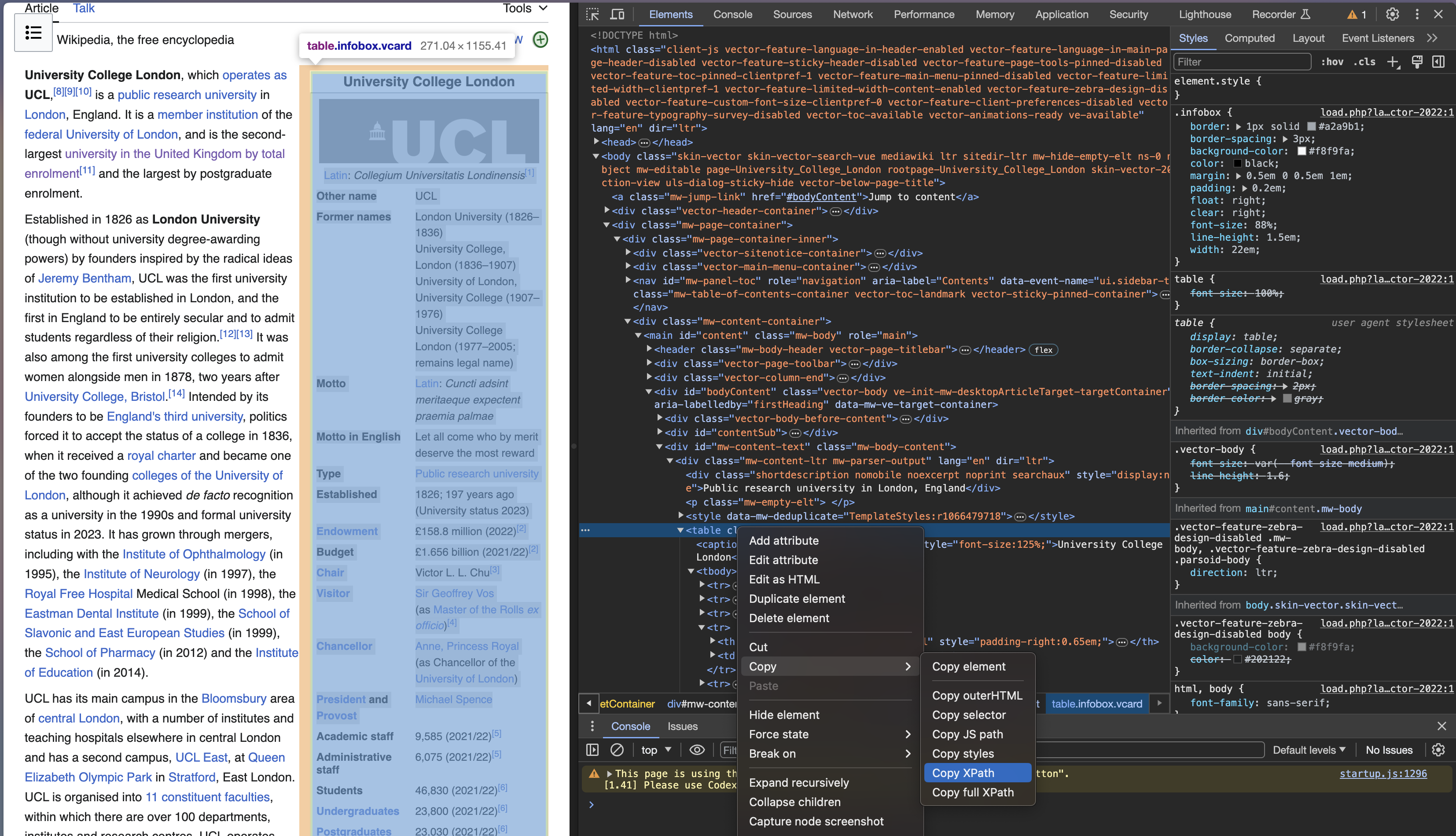
Let’s inspect a website
- Use inspect option to select table to copy
Xpath–example://*[@id="mw-content-text"]/div[1]/table[1]
Extracting selected information
- Select the desired part
- Convert to table

Automating the process
The task is to scrap Wiki info-cards of three universities (UCL; Oxford; Cambridge)
#see whether path is allowed to be scraped
paths_allowed(paths="https://en.wikipedia.org/wiki/University_College_London")
#creating url list for the websites to be scraped
url_list <- c(
"https://en.wikipedia.org/wiki/University_College_London",
"https://en.wikipedia.org/wiki/University_of_Cambridge",
"https://en.wikipedia.org/wiki/University_of_Oxford"
)
Scraping tables
testlink <- read_html("https://en.wikipedia.org/wiki/University_College_London")
table <- testlink %>%
html_nodes(xpath='//*[@id="mw-content-text"]/div[1]/table[2]') %>%
html_table()
table <- data.frame(table)
table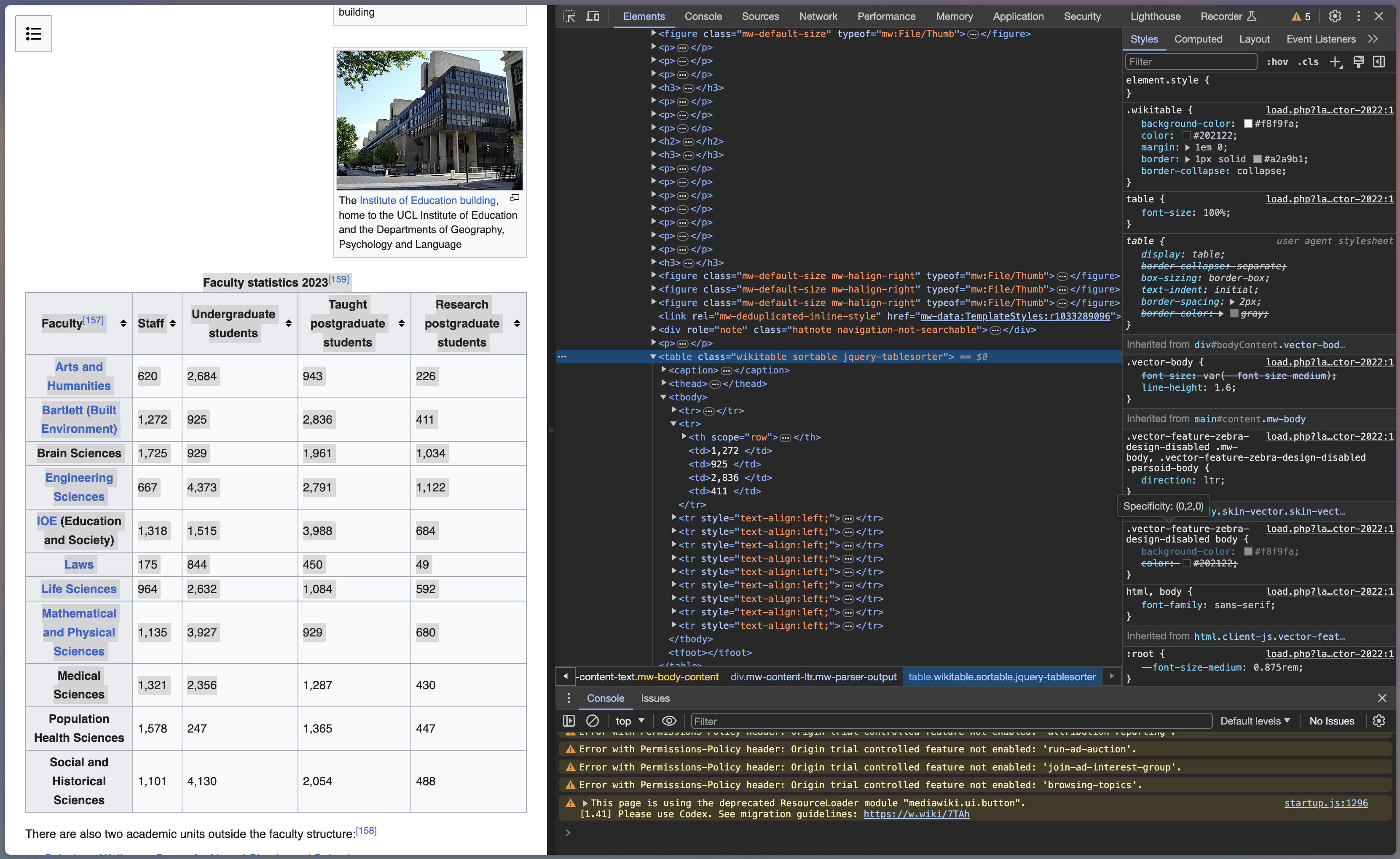
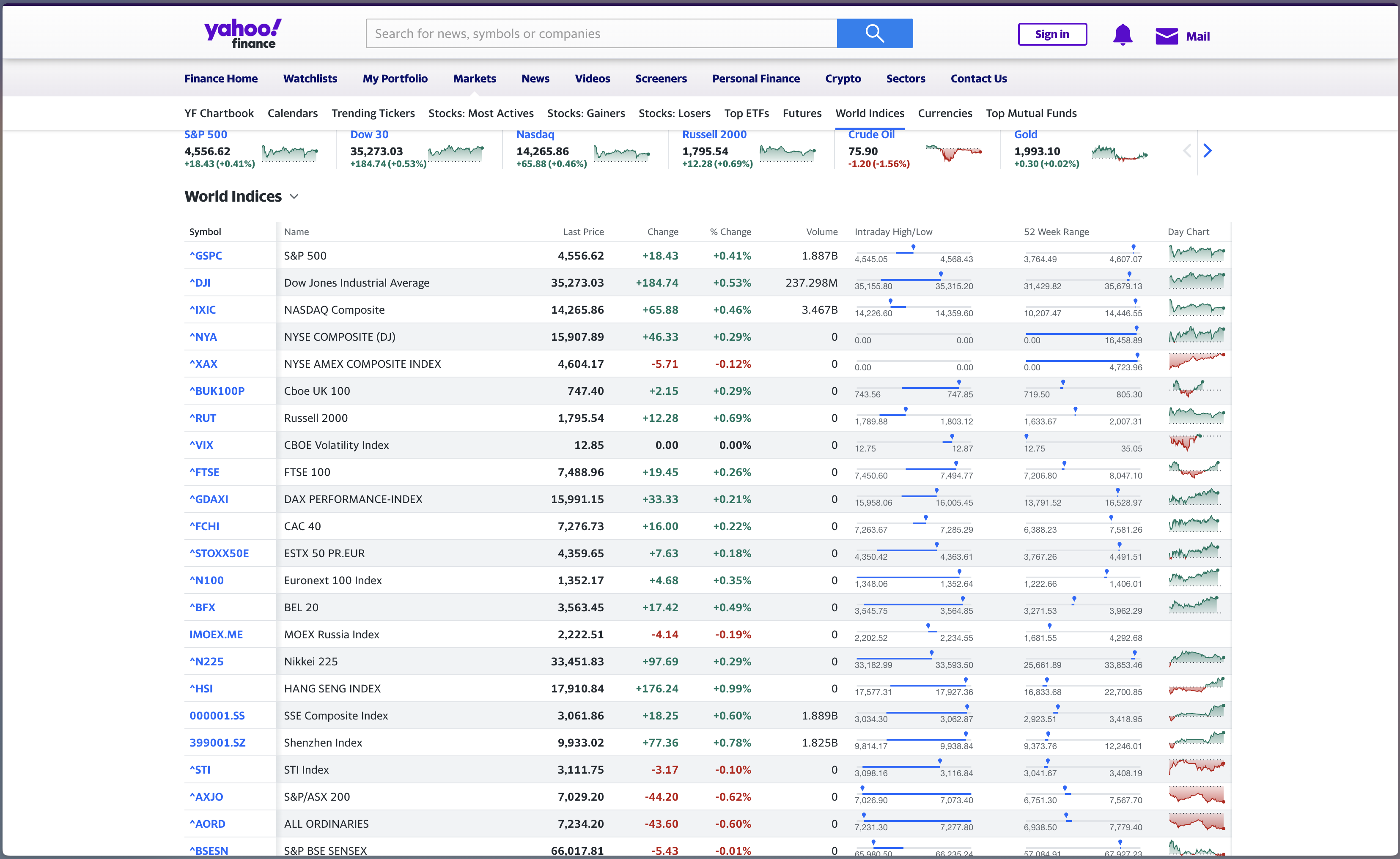
Lab exercise: Scraping global indicies table on Yahoo finance
Load required libraries
Check whether scraping is permitted on Yahoo Finance (https://finance.yahoo.com/world-indices/)
Identify XPath for the table, read the path (read_html)
Keep only the columns: (Name, Last Price, % Change)
Save this information as a new data frame (yahoo_data)
Use
plotlyto create a bar plot to visualise stock indicies prices and changes
![]()