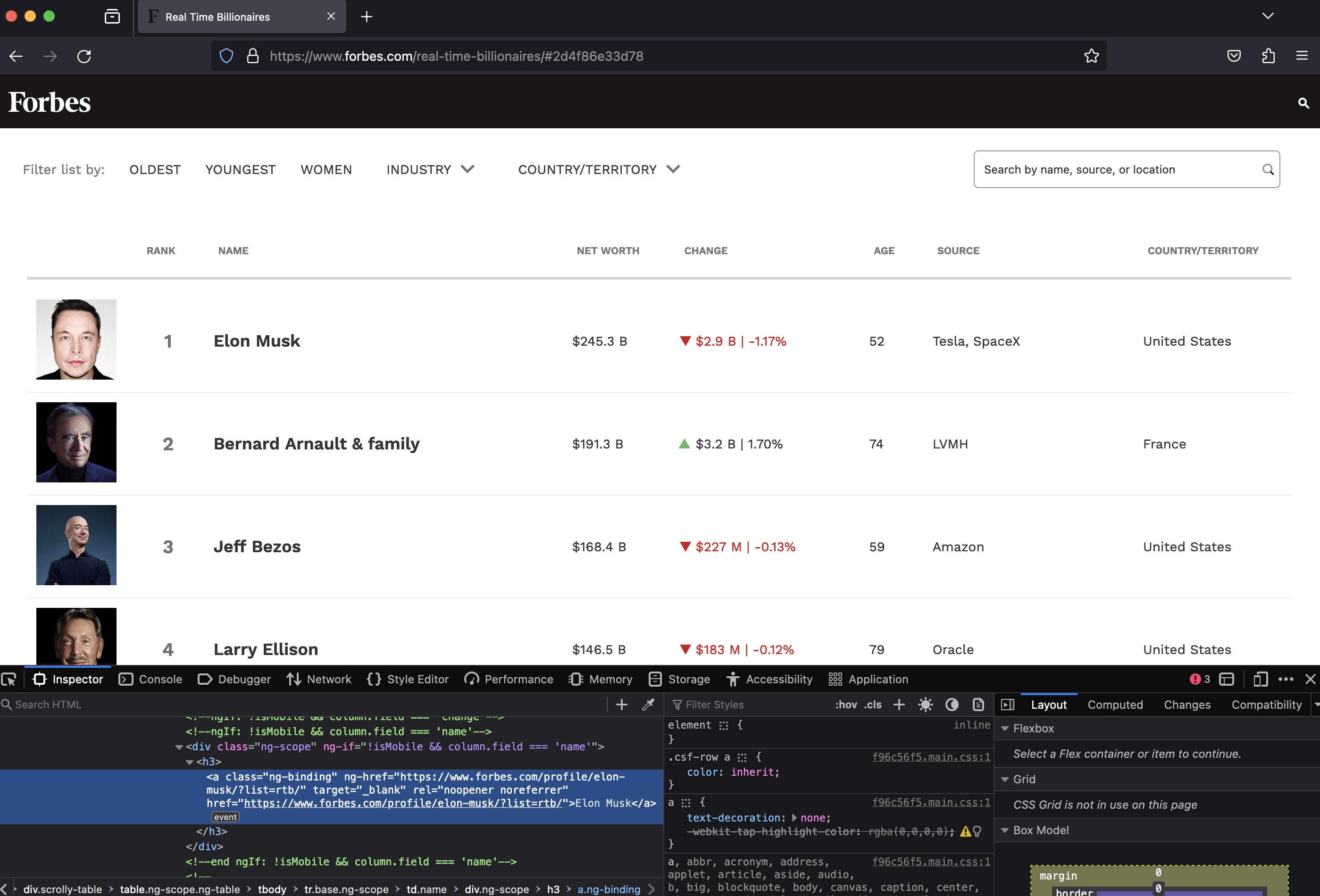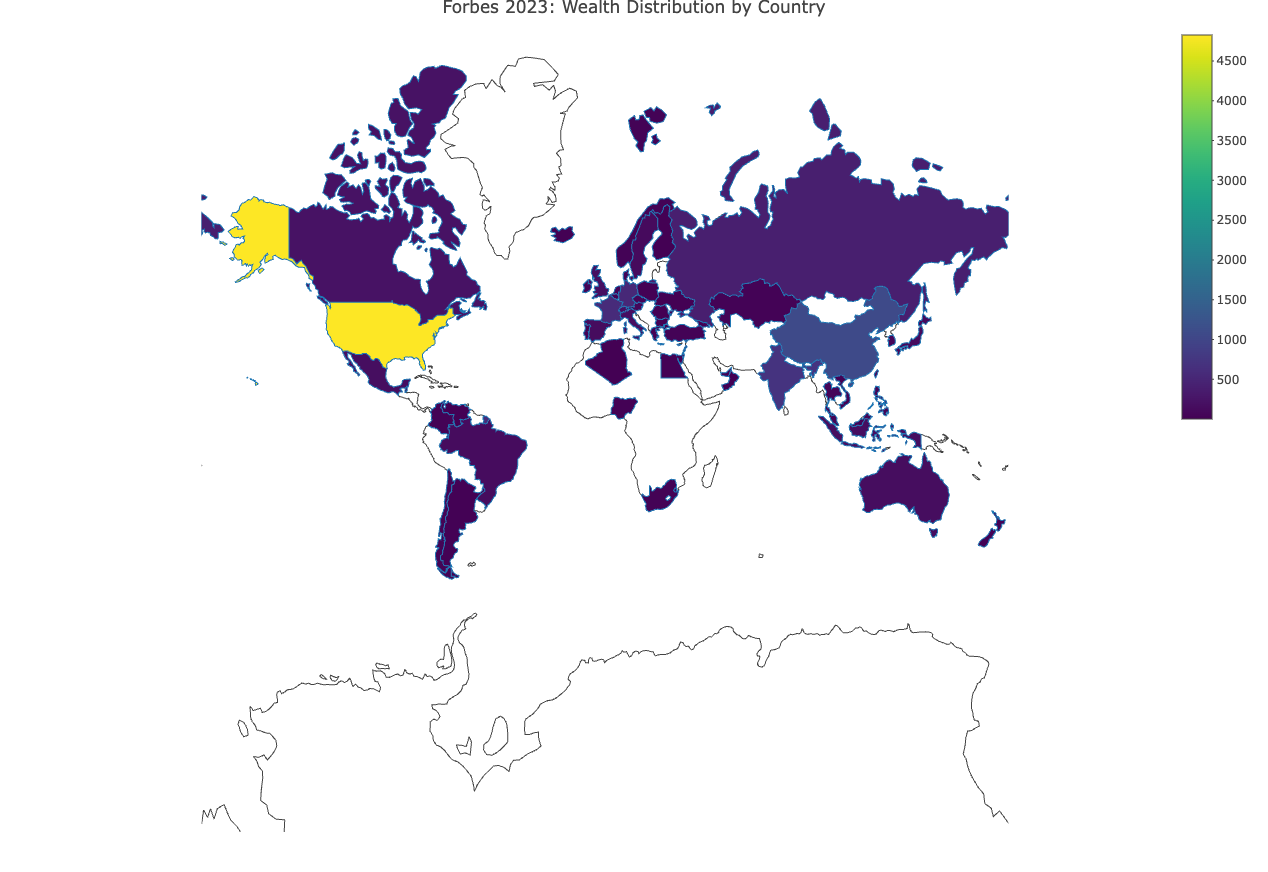
The downloaded binary packages are in
/var/folders/f6/gb9b_pqd0yg5tl9h5791zmjr0000gp/T//Rtmp4tUZOE/downloaded_packages
The downloaded binary packages are in
/var/folders/f6/gb9b_pqd0yg5tl9h5791zmjr0000gp/T//Rtmp4tUZOE/downloaded_packages [1] "null" "cancel" "help" "backspace" "tab"
[6] "clear" "return" "enter" "shift" "control"
[11] "alt" "pause" "escape" "space" "page_up"
[16] "page_down" "end" "home" "left_arrow" "up_arrow"
[21] "right_arrow" "down_arrow" "insert" "delete" "semicolon"
[26] "equals" "numpad_0" "numpad_1" "numpad_2" "numpad_3"
[31] "numpad_4" "numpad_5" "numpad_6" "numpad_7" "numpad_8"
[36] "numpad_9" "multiply" "add" "separator" "subtract"
[41] "decimal" "divide" "f1" "f2" "f3"
[46] "f4" "f5" "f6" "f7" "f8"
[51] "f9" "f10" "f11" "f12" "command_meta"