🗓️ Week 09
Working with APIs
06 Dec 2024
RESTful Web APIs
- They are all around you
- consider a simple Google search:
- Ever wonder what all that extra stuff in the address bar was all about?
- the full address is Google’s way of sending a query to its databases requesting information related to the search term “university college london”
Anatomy of API
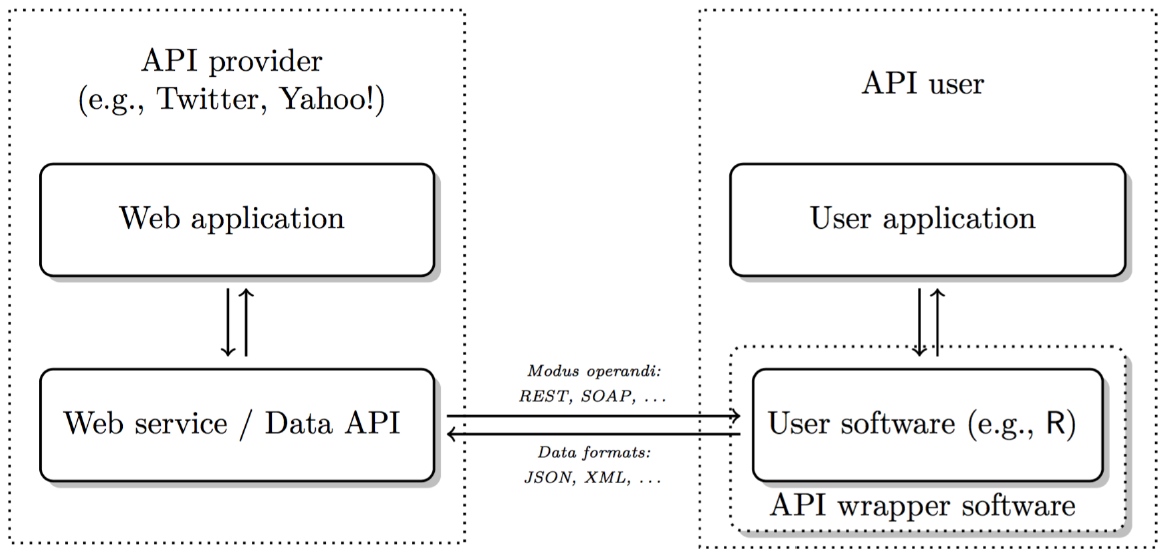
- API = Application Programming Interface
- a set of structured http requests that return data in a lightweight format
- HTTP = Hypertext Transfer Protocol
- how browsers and e-mail clients communicate with servers
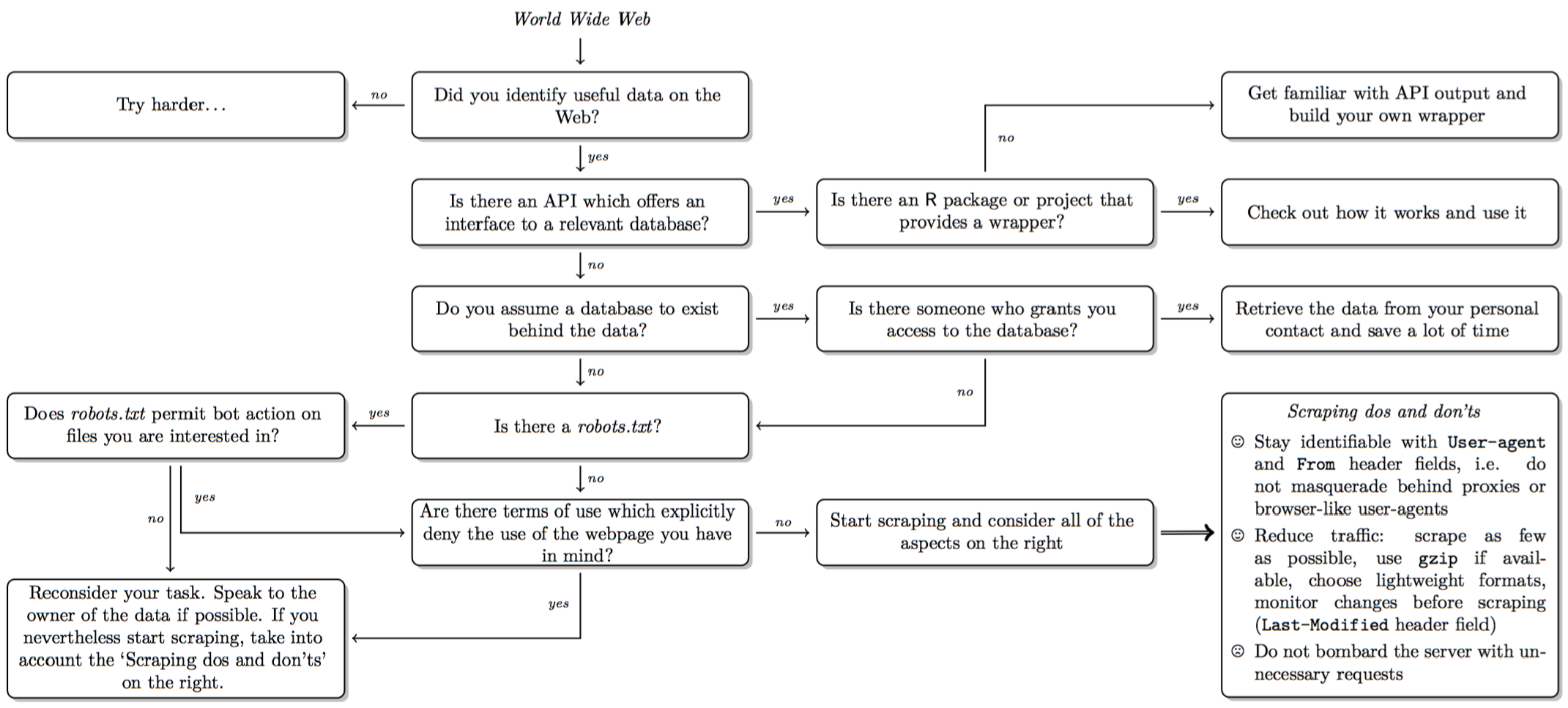
Decision in scraping
(Reponse) Formats: XML
- XML (eXtensibleMarkupLanguage, *.xml)
- plain text format like JSON
- syntax of choice for many newly designed document formats (Word documents!)
- looks like HTML but has purpose to store data: Markup (mostly tags) & content
Json vs XML:

Getting API Access
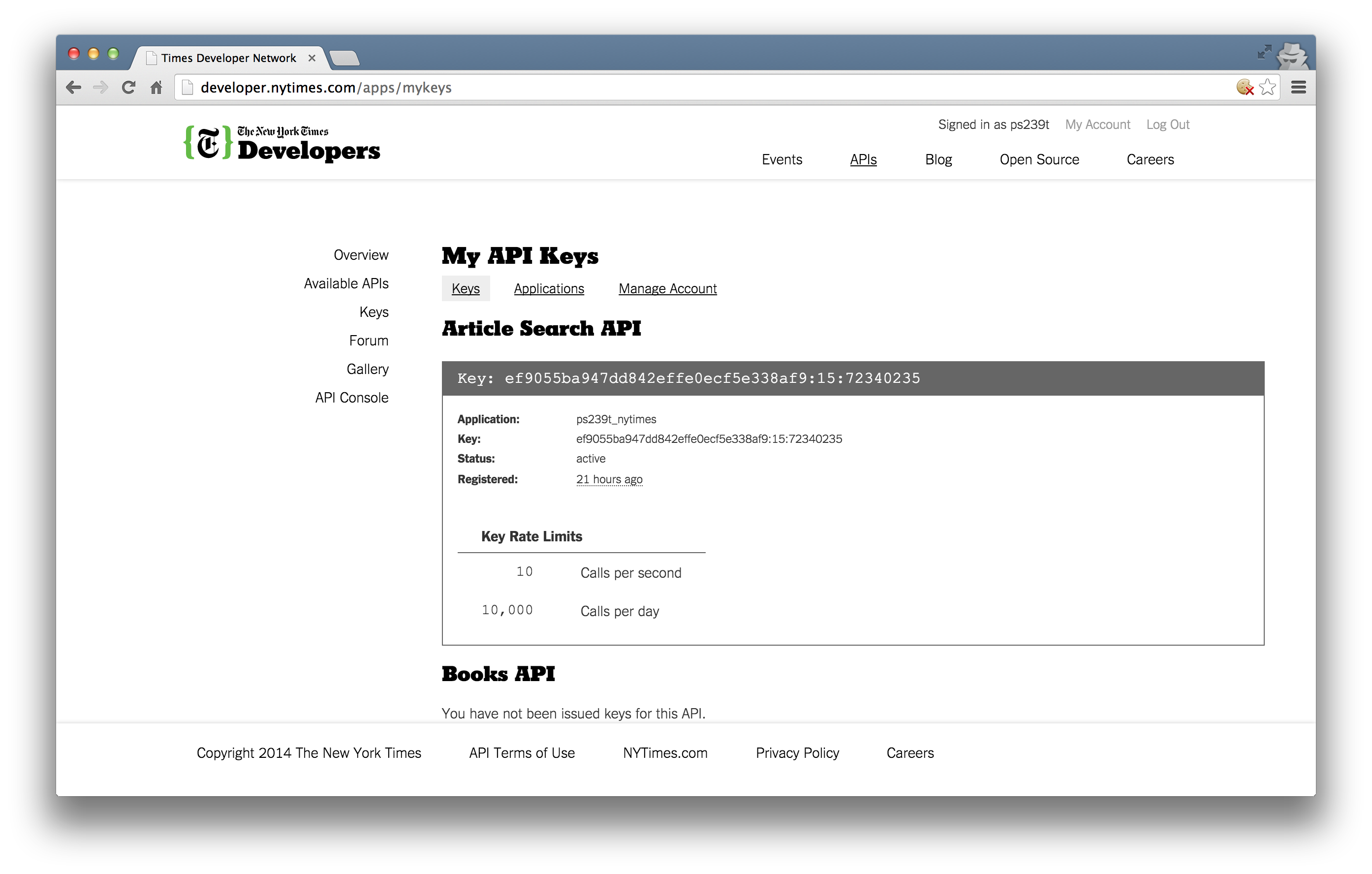
Most APIs requires a key or other user credentials before you can query their database
Getting credentialised with a API requires that you register with the organization
Most APIs are set up for developers, so you will likely be asked to register an application
Once you have successfully registered, you will be assigned one or more keys, tokens, or other credentials that must be supplied to the server as part of any API call you make
Using gtrendsR Package
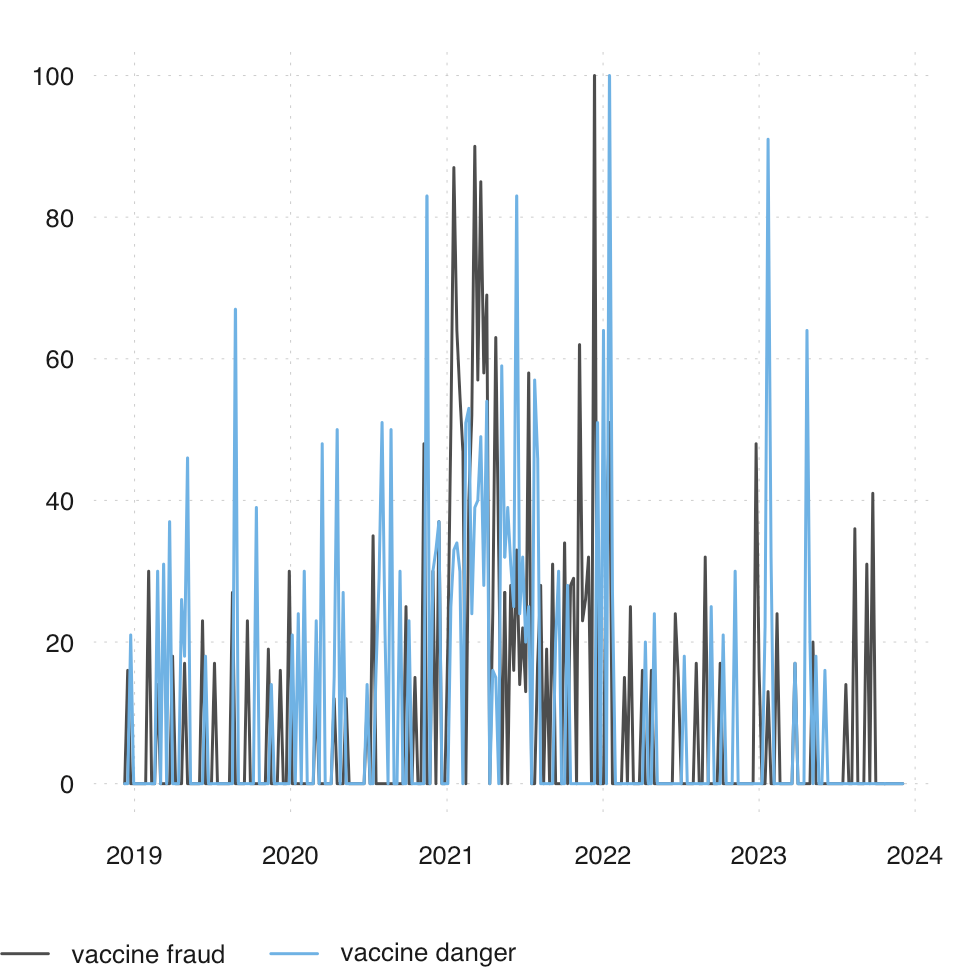
- Visualising google search activity for the word “vaccine fraud” and “vaccine danger” in UK
data("countries") # get abbreviations of all countries to filter data
data("categories") # get numbers of all categories to filter data
#Combination using dplyr and ggplot
trend <- gtrends(keyword="vaccine", geo=c("GB"), time = "2021-01-01 2021-12-30", gprop="web")
trend_df <- trend$interest_over_time
trend_df <- trend_df %>%
mutate(hits = as.numeric(hits), date = as.Date(date)) %>%
replace(is.na(.), 0)
ggplot(trend_df, aes(x=date, y=hits, group=geo, col=geo)) + geom_line(size=2) +
scale_x_date(date_breaks = "2 months" , date_labels = "%b-%y") +
labs(color= "Countries") +
ggtitle("Frequencies for the query -vaccine harm- in the period: 2021-01-01 - 2021-12-3")
#if gtrendsR package doesn't work, try trendecon package
library(trendecon)
x <- ts_gtrends(keyword = c("vaccine fraud", "vaccine danger"), geo = c("GB"), time = "today+5-y",
retry = 5,
wait = 10)
tsbox::ts_plot(x)Using Google Maps API
ggmapuses Google Maps behind the scenes, so you’ll need an active Google Cloud Platform account (see here if you cannot figure out)- enable the following APIs under APIs and Services – Library:
- Maps JavaScript API
- Maps Static API
- Geocoding API
- enable the following APIs under APIs and Services – Library:
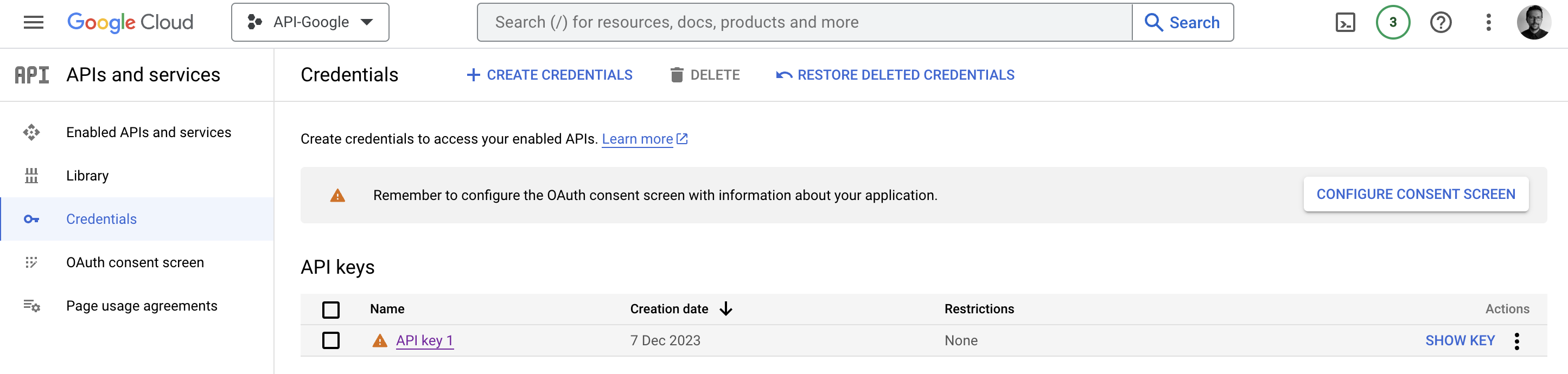
How to use ggmap with Google Maps API
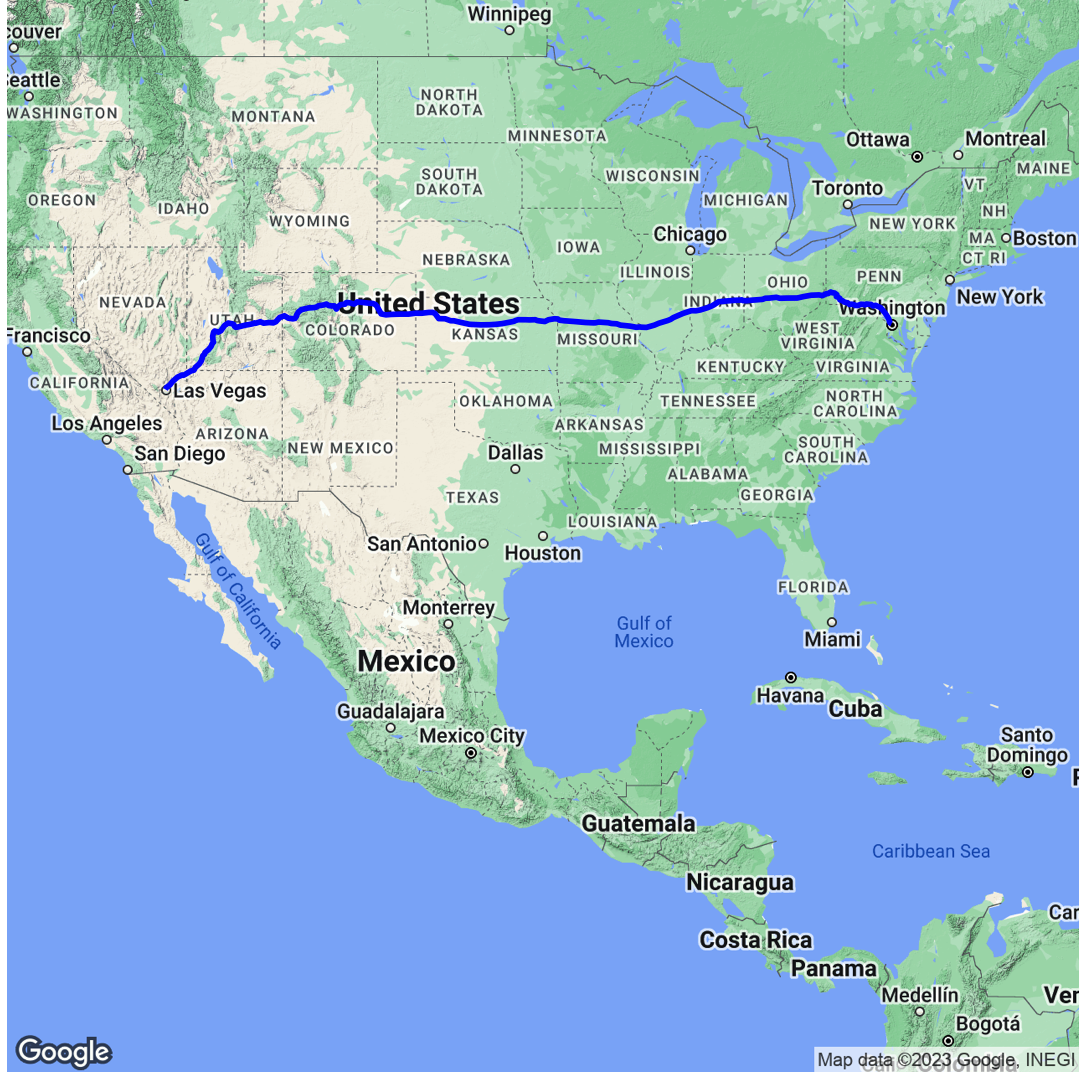
Visualising locations of charities
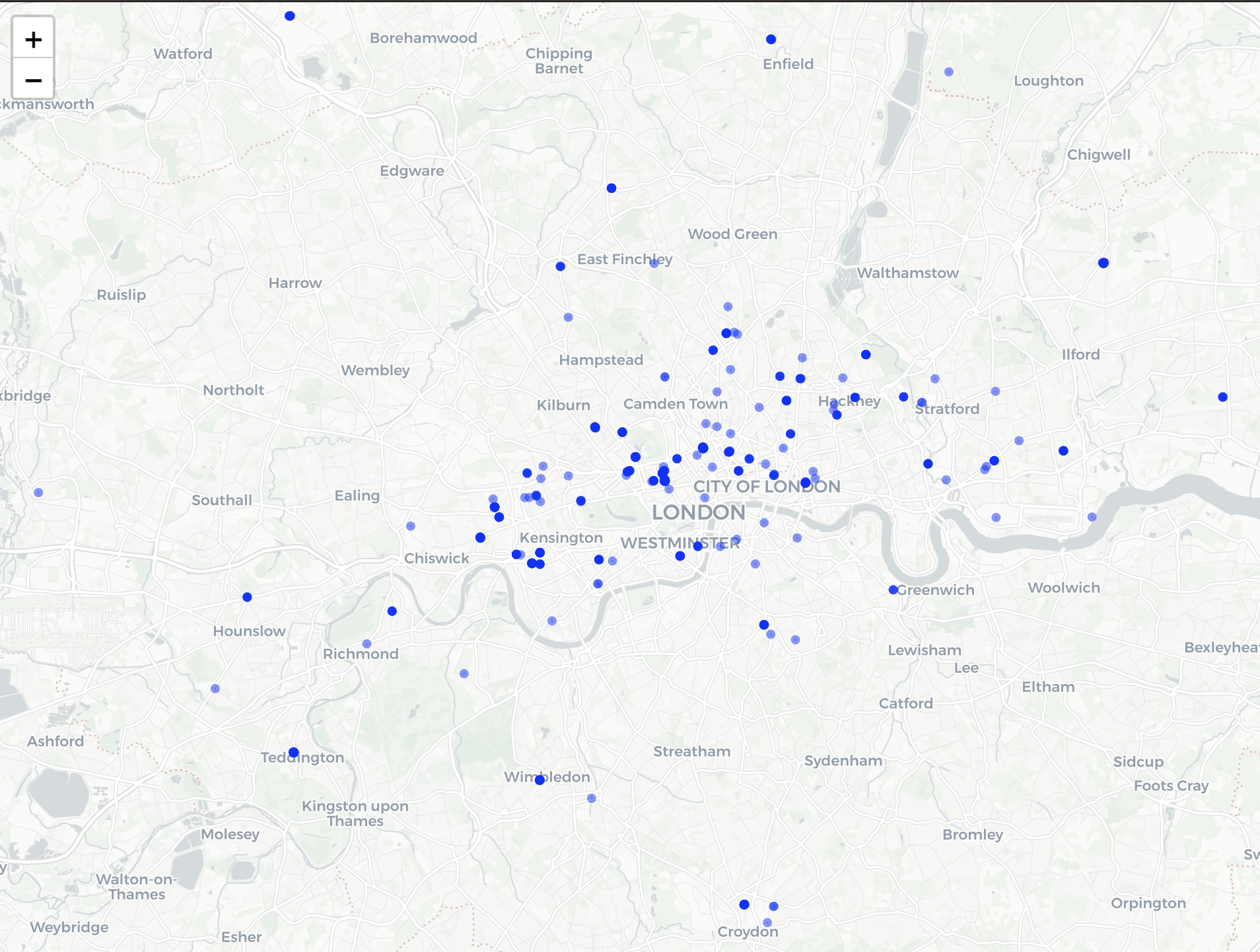
Lab exercise and further materials
- Visualise location of pubs in Greater London, using OpenStreetMap API
Further texts:
Bonus Tutorial: Spotify API: